PySpark Certification Training Course in Gurgaon
PySpark is a data processing tool that is used to build ETL jobs to configure Data Pipelines & perform all the business rules & validation across the pipeline using PySpark rich library. It combines Data warehousing, ETL Processing capability using Spark Engine to bring end-to-end (E2E) ETL solution from Data ingestion to hydration to transformation using Spark Executor.
- Develop ETL scripts/templates to build ETL Jobs using Spark Engine that will reduce costing & speed-up ETL deployment.
- Training program will provide interactive sessions with industry professionals
- Realtime project expereince to crack job interviews

- Course Duration - 3 months
- Get training from Industry Professionals
Train using realtime course materials using online portals & trainer experience to get a personalized teaching experience.
Active interaction in sessions guided by leading professionals from the industry
Gain professionals insights through leading industry experts across domains
24/7 Q&A support designed to address training needs
PySpark Certification Training Course Overview
Start your carrer in Data with PySpark that is a data processing tool used to build ETL jobs to configure Data Pipelines & perform all the business rules & validation across the pipeline using PySpark rich library. It combines Data warehousing, ETL Processing capability using Spark Engine to bring end-to-end (E2E) ETL solution from Data ingestion to hydration to transformation using Spark Executor.
- Benefit from ongoing access to all self-paced videos and archived session recordings
- Success Aimers supports you in gaining visibility among leading employers
- Industry-paced training with realtime scenarios using PySpark for ETL automation.
- Real-World industry scenarios with projects implementation support
- Live Virtual classes heading by top industry experts alogn with project implementation
- Q&A support sessions
- Job Interview preparation & use cases

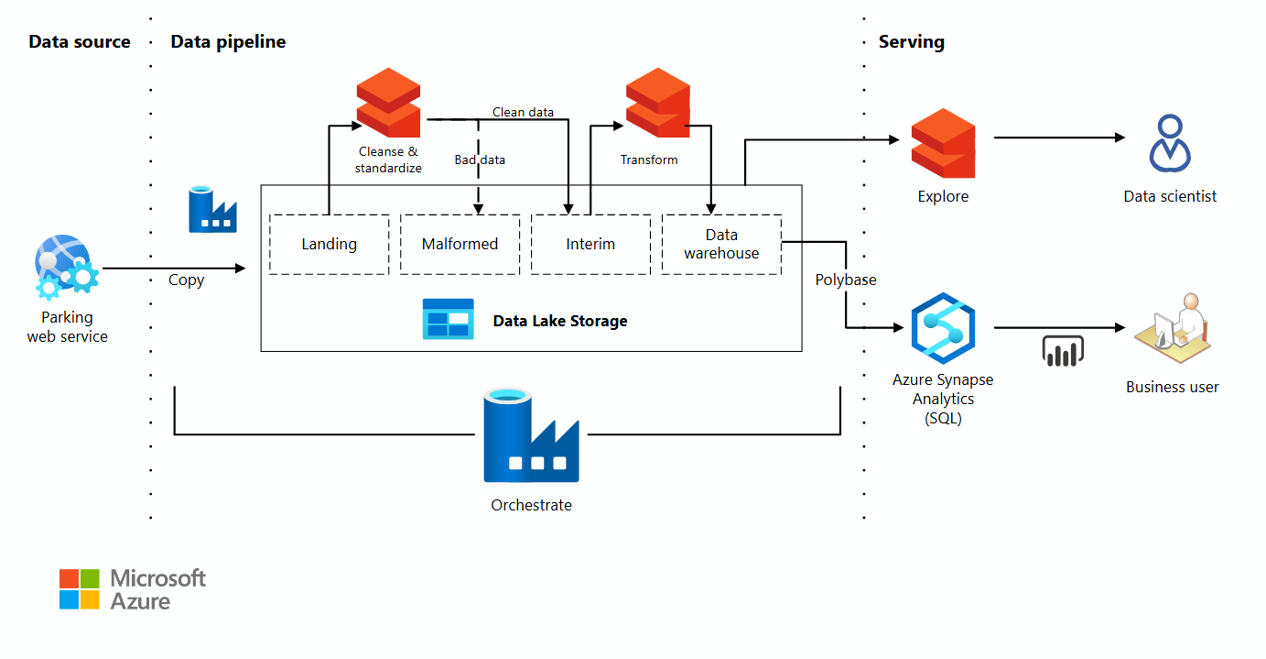
Explain PySpark Data Engineers?
PySpark Data Engineers build ETL/Data pipelines using Spark. PySpark helps data engineers to build & develop ETL workflows & manage ETL job dependencies using PySpark pipeline orchestrator. It also helps to hydrate/ingest data from various data sources using the pre-built connectors available.
Role of PySpark Data Engineer?
PySpark Data Engineers automate/build Data/ETL pipelines using Spark Engine.
Responsibilities include:
- PySpark Data engineers use Visual Studio & others IDE’s to write Spark/ETL scripts to automate/build ETL pipelines.
- PySpark Data Engineers manages the end-to-end Data orchestration life cycle using ETL workflows and Spark templates.
- Develop and Design PySpark workflows that automate ETL (GLUE/PySpark/Databricks) job pipelines securely & seamlessly
- Success Aimers helps aspiring PySpark professionals to build, deploy, manage Data Pipelines using Spark templates effectively & seamlessly.
- Deploying PySpark scripts within cloud infrastructure securely & seamlessly.
Who should opt for PySpark Data Engineer course?
PySpark Data Engineer course accelerates/boost career in Data & Cloud organizations.
- PySpark Data Engineers – PySpark Engineers manages the end-to-end Data Orchestration life cycle using PySpark workflow and connectors.
- PySpark Data Engineers – Implementing ETL Pipelines using PySpark Tools.
- PySpark Developers – Automated ETL pipeline deployment workflows using PySpark Tools.
- ETL/Data Architect – Leading Data initiative within enterprise.
- Data and AI Engineers – Deploying ETL Application using AWS DevOps automation tools including PySpark to orchestrate pipelines seamlessly and effectively.
Prerequisites of PySpark Data Engineer Course?
Prerequisites required for the PySpark Data Engineer Certification Course
- High School Diploma or a undergraduate degree
- Python + JSON/YAML scripting language
- IT Foundational Knowledge along with DevOps and cloud infrastructure skills
- Knowledge of Cloud Computing Platforms like AWS, AZURE and GCP will be an added advantage.
Kind of Job Placement/Offers after PySpark Data Engineer Certification Course?
Job Career Path in ETL (Cloud) Automation using PySpark
- PySpark Data Engineer – Develop & Deploying PySpark ETL scripts within cloud infrastructure using Azure DevOps tools & orchestrate it by using PySpark & similar tools.
- PySpark Automation Engineer – Design, Developed and build automated PySpark ETL workflows to drive key business processes/decisions.
- PySpark Data Architect – Leading Data initiative within enterprise.
- PySpark Data Engineers – Implementing ETL Pipelines using PySpark & Tools.
- Cloud and Data Engineers – Deploying ETL Application using Azure DevOps automation tools including PySpark across environments seamlessly and effectively.
| Training Options | Weekdays (Mon-Fri) | Weekends (Sat-Sun) | Fast Track |
|---|---|---|---|
| Duration of Course | 2 months | 3 months | 15 days |
| Hours / day | 1-2 hours | 2-3 hours | 5 hours |
| Mode of Training | Offline / Online | Offline / Online | Offline / Online |
PySpark Course Curriculum
Start your carrer in Data with certification in PySpark Data Engineer course, that will help in shaping the carrer to the current industry needs that need ETL automation/scheduling using intelligent PySpark workflows like Fabric, Control-M, Apache Oozie & others that allow organizations to boost decision making & also thrive business growth with improved customer satisfaction.
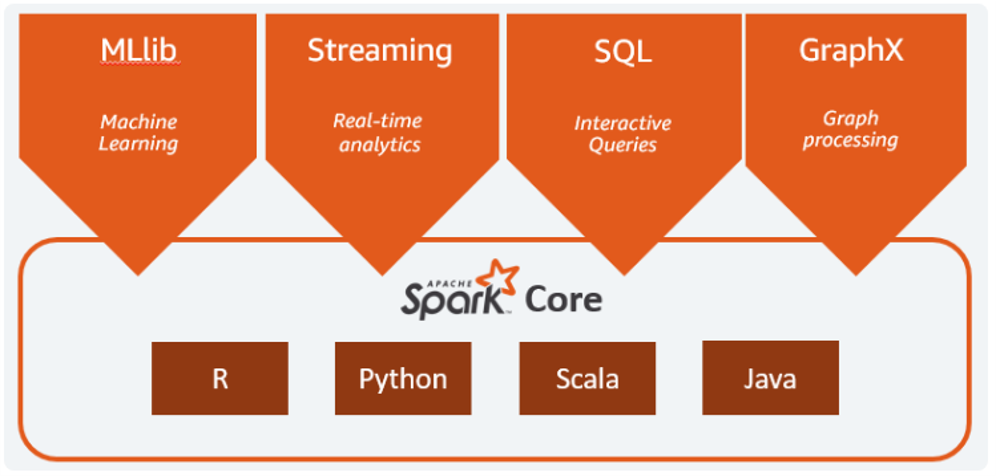
Apache PySpark
Understanding Big Data and Distributed Data Processing
- What is Big Data and How it Started
- Hadoop Architecture, History and Evolution
- Data Lake and Lakehouse Architecture
Introduction to Apache Spark (Spark Installation, Components & Architecture)
- What is Apache Spark
- Apache Spark System Architecture
- Apache Spark Components & Architecture
- Spark Platform and Development Environment
- What is Databricks Cloud
- Create your Databricks Free Account
- Setup your hands-on environment
- Spark Installation
- Spark Main Components
- Spark & its features
- Deployment Modes of Spark
- Introduction to PySpark Shell
- Submitting PySpark Jobs
- Utilizing Spark Web UI
Getting started with Spark Programming
- Starting Point - Spark Session
- Introduction to Spark Session
- Spark Object and Spark Submit Part 1
- Spark Object and Spark Submit Part 2
- Spark Object and Spark Submit Part 3
- DataFrame – A view to Structured data
- DataFrame Transformations and Actions
- DataFrame Concepts
- Exploring DataFrame Transformations
- Creating Spark DataFrame
Spark Cluster Execution Architecture
- Full Architecture
- YARN As Spark Cluster Manager
- JVMs across Clusters
- Commonly Used Terms in Execution Frame
- Narrow and Wide Transformations
- DAG Scheduler Part 1
- DAG Scheduler Part 2
- DAG Scheduler Part 3
- Task Scheduler
Spark Shared Variables
- Broadcast Variable
- Accumulator Variable
Spark SQL Introduction & Architecture
- Spark SQL Architecture Part 1
- Spark SQL Architecture Part 2
- Spark SQL Architecture Part 3
- Spark SQL Architecture Part 4
- Spark SQL Architecture Part 5
- Spark SQL Architecture Part 6
- Spark SQL Architecture Part 7
- Spark SQL Architecture Part 8
- Working with SQL Context and Schema RDDs
- User Defined Functions (UDFs) in Spark SQL
- Data Frames, Datasets, and Interoperability with RDDs
- Loading Data from Different Sources
- Integration of Spark with Hive for Data Warehousing
Spark Session Features
- Introduction to Spark Session
- Spark Object and Spark Submit Part 1
- Spark Object and Spark Submit Part 2
- Spark Object and Spark Submit Part 3
- Version and Range
- createDataFrame
- Table
- sparkContext
- udf
- read-csv
- read-text
- read-orc and parquet
- read-json
- read-avro
- read-hive
- read-jdbc
- Catalog
DataFrame Fundamentals
- Introduction to DataFrame
- DataFrame Features - Distributed
- DataFrame Features - Lazy Evaluation
- DataFrame Features - Immutability
- DataFrame Features - Other Features
- Organization
DataFrame ETL
- Introduction to Transformations and Extraction
- DataFrame APIs Introduction Extraction
- DataFrame APIs Selection
- DataFrame APIs Filter or Where
- DataFrame APIs Sorting
- DataFrame APIs Set
- DataFrame APIs Join
- DataFrame APIs Aggregation
- DataFrame APIs GroupBy
- DataFrame APIs Window Part 1
- DataFrame APIs Window Part 2
- DataFrame APIs Sampling Functions
- DataFrame APIs Other Aggregate Functions
- DataFrame Built-in Functions Introduction
- DataFrame Built-in Functions - New Column Functions
- DataFrame Built-in Functions - Column Encryption
- DataFrame Built-in Functions - String Functions
- DataFrame Built-in Functions - RegExp Functions
- DataFrame Built-in Functions - Date Functions
- DataFrame Built-in Functions - Null Functions
- DataFrame Built-in Functions - Collection Functions
- DataFrame Built-in Functions - na Functions
- DataFrame Built-in Functions - Math and Statistics Functions
- DataFrame Built-in Functions - Explode and Flatten Functions
- DataFrame Built-in Functions - Formatting Functions
- DataFrame Built-in Functions - Json Functions
- Need of Repartition and Coalesce
- How to Repartition a DataFrame
- How to Coalesce a DataFrame
- Repartition Vs Coalesce Method of a DataFrame
- DataFrame Extraction Introduction
- DataFrame Extraction - csv
- DataFrame Extraction - text
- DataFrame Extraction - Parquet
- DataFrame Extraction - orc json
- DataFrame Extraction - avro
- DataFrame Extraction - hive
- DataFrame Extraction - jdbc
DataFrame Transformations
- Adding, Removing, and Renaming Columns
- DataFrame Column Expressions
- Filtering and removing duplicates
- Sorting, Limiting and Collecting
- Transforming Unstructured data
- Transforming data with LLM
Working with different Data Types
- Working with Nulls
- Working with Numbers
- Manipulating Strings
- Working with Date
- Working with Timestamps
- Handling Time Zone Information
- Working with Complex Data Types
- Working with JSON data
- Working with Variant Type
Joins in Spark DataFrame
- Introduction to Joins in Spark
- Inner Joins
- Outer Joins
- Lateral Join
- Other Types of Joins
Aggregations in Spark Dataframe
- Simple Aggregation
- Grouping Aggregation
- Multilevel Aggregation
- Windowing Aggregation
UDF and Unit Testing
- User-Defined Functions
- Vectorized UDF
- User Defined Table Functions
- Unit Testing Spark Code
Spark Execution Model
- Execution Methods - How to Run Spark Programs?
- Spark Distributed Processing Model - How your program runs?
- Spark Execution Modes and Cluster Managers
- Summarizing Spark Execution Models - When to use What?
- Working with PySpark Shell - Demo
- Installing Multi-Node Spark Cluster - Demo
- Working with Notebooks in Cluster - Demo
- Working with Spark Submit - Demo
Spark Programming Model and Developer Experience
- Creating Spark Project Build Configuration
- Configuring Spark Project Application Logs
- Creating Spark Session
- Configuring Spark Session
- Data Frame Introduction
- Data Frame Partitions and Executors
- Spark Transformations and Actions
- Spark Jobs Stages and Task
- Understanding your Execution Plan
Spark Structured API Foundation
- Introduction to Spark APIs
- Introduction to Spark RDD API
- Working with Spark SQL
- Spark SQL Engine and Catalyst Optimizer
- Setting Up Glue Data Quality CloudWatch Metrics
- Receiving Alerts for Data Quality Issues
Spark Data Sources and Sinks
- Spark Data Sources and Sinks
- Spark DataFrameReader API
- Reading CSV, JSON and Parquet files
- Creating Spark DataFrame Schema
- Spark DataFrameWriter API
- Writing Your Data and Managing Layout
- Spark Databases and Tables
- Working with Spark SQL Tables
Spark DataFrame and Dataset Transformations
- Introduction to Data Transformation
- Working with DataFrame Rows
- DataFrame Rows and Unit Testing
- DataFrame Rows and Unstructured data
- Working with DataFrame Columns
- Misc Transformations
Spark DataFrame and Dataset Joins
- DataFrame Joins and column name ambiguity
- Outer Joins in DataFrame
- Internals of Spark Join and shuffle
- Optimizing your joins
- Implementing Bucket Joins
Optimizing Data Frame Transformations
General Join Mechanisms
- Shuffled Join
- Optimized Join
- Broadcast Join
- Caching & Checkpointing
- Skew Joins
Partitioning
- Repartition & Coalesce
- Shuffle Partitions
- Custom Partitioners
Performance Tuning Problems
- Optimizing Cluster Resource Allocation
- Serialization Problem
- Fixing Data Skew (Data Skewness) & Straggling Task
- Column Pruning
Optimizing Apache Spark on Databricks (Performance & Optimization)
- Five Most Common Problems with Spark Applications
- Key Ingestion Concepts
- Optimizing with Adaptive Query Execution & Dynamic Partition Pruning
- Designing Clusters for High Performance
- Join Strategies_01_Broadcast Join
- Join Strategies_02_Shuffle Hash Join
- Join Strategies_03_Shuffle Sort Merge Join
- Join Strategies_04_Cartesian Product Join
- Join Strategies_05_Broadcast Nested Loop Join
- Join Strategies_06_Prioritize different Join strategy
- Driver Configurations
- Executor Configurations Part 1
- Executor Configurations Part 2
- Configurations in spark-submit
- Parallelism Configurations
- Memory Management
Capstone Project
- Project Scope and Background
- Data Transformation Requirement
- Setup your starter project
- Test your starter project
- Setup your source control and process
- Creating your Project CI CD Pipeline
- Develop Code
- Write Test Cases
- Working with Kafka integration
- Estimating resources for your application
Develop a Data Pipeline using PySpark ETL to ingest data from hybrid sources (API, HTTP interfaces, databases & others) into DW’s & Delta Lake) & orchestrate/schedule it by using PySpark Pipelines.
Project Description : Data will be hydrated from various sources into the raw layer (Bronze Layer) using PySpark connectors. Further it will be processed through silver layer/table after data standardization & cleansing process. From curated layer (silver layer) PySpark jobs populate the target layer (gold layer) after business transformation that will derive key business insights. The whole pipeline will be automated by using ETL orchestration tool PySpark workflow.
Project 2
Developed Data Ingestion Pipeline using PySpark
The Data Pipeline will be automated through orchestration tools like Apache Airflow, Oozie, Control-M & others that orchestrate PySpark jobs to triggers sequentially & perform the Data ingestion, transformation & loading activities through the various layers of our Data Pipelines like landing layer that contains raw feeds , then to curated zone that will be populated using Spark jobs after performing Data standardization & cleansing & finally data will be updated to the derived zone after performing the business rules & data validations. PySpark jobs performance will be monitored via Spark DAG’s.
Hours of content
Live Sessions
Software Tools



After completion of this training program you will be able to launch your carrer in the world of Data being certified as PySpark Professional.
With the PySpark Certification in-hand you can boost your profile on Linked, Meta, Twitter & other platform to boost your visibility

- Get your certificate upon successful completion of the course.
- Certificates for each course
- PySpark
- DevOps
- CI/CD
- Python
- Spark Executor
- Spark SQL
- Spark Streaming
- Spark Core
- Spark Dataframe
- Spark Dataset
- Spark API
- Kubernetes
- AWS Glue
- Docker

35% - 65%











Designed to provide guidance on current interview practices, personality development, soft skills enhancement, and HR-related questions

Receive expert assistance from our placement team to craft your resume and optimize your Job Profile. Learn effective strategies to capture the attention of HR professionals and maximize your chances of getting shortlisted.

Engage in mock interview sessions led by our industry experts to receive continuous, detailed feedback along with a customized improvement plan. Our dedicated support will help refine your skills until your desired job in the industry.

Join interactive sessions with industry professionals to understand the key skills companies seek. Practice solving interview question worksheets designed to improve your readiness and boost your chances of success in interviews

Build meaningful relationships with key decision-makers and open doors to exciting job prospects in Product and Service based partner

Your path to job placement starts immediately after you finish the course with guaranteed interview calls
Why should you choose to pursue a PySpark Data Engineer course with Success Aimers?
Success Aimers teaching strategy follow a methodology where in we believe in realtime job scenarios that covers industry use-cases & this will help in building the carrer in the field of PySpark & also delivers training with help of leading industry experts that helps students to confidently answers questions confidently & excel projects as well while working in a real-world
What is the time frame to become competent as a PySpark Data engineer?
To become a successful PySpark Data Engineer required 1-2 years of consistent learning with dedicated 3-4 hours on daily basis.
But with Success Aimers with the help of leading industry experts & specialized trainers you able to achieve that degree of mastery in 6 months or one year or so and it’s because our curriculum & labs we had formed with hands-on projects.
Will skipping a session prevent me from completing the course?
Missing a live session doesn’t impact your training because we have the live recorded session that’s students can refer later.
What industries lead in PySpark implementation?
Manufacturing
Financial Services
Healthcare
E-commerce
Telecommunications
BFSI (Banking, Finance & Insurance)
“Travel Industry
Does Success Aimers offer corporate training solutions?
At Success Aimers, we have tied up with 500 + Corporate Partners to support their talent development through online training. Our corporate training programme delivers training based on industry use-cases & focused on ever-evolving tech space.
How is the Success Aimers PySpark Certification Course reviewed by learners?
Our PySpark Data Engineer Course features a well-designed curriculum frameworks focused on delivering training based on industry needs & aligned on ever-changing evolving needs of today’s workforce due to Data and AI. Also our training curriculum has been reviewed by alumi & praises the through content & real along practical use-cases that we covered during the training. Our program helps working professionals to upgrade their skills & help them grow further in their roles…
Can I attend a demo session before I enroll?
Yes, we offer one-to-one discussion before the training and also schedule one demo session to have a gist of trainer teaching style & also the students have questions around training programme placements & job growth after training completion.
What batch size do you consider for the course?
On an average we keep 5-10 students in a batch to have a interactive session & this way trainer can focus on each individual instead of having a large group
Do you offer learning content as part of the program?
Students are provided with training content wherein the trainer share the Code Snippets, PPT Materials along with recordings of all the batches

Apache Airflow Training Course in Gurgaon Orchestrating ETL pipelines using Apache Airflow for scheduling and...

AWS Glue Lambda Training Course in Gurgaon AWS GLUE is a Serverless cloud-based ETL service...

Azure Data Factory Certification Training Course in Gurgaon Orchestrating ETL pipelines using Azure Data Factory...

Azure Synapse Certification Training Course in Gurgaon Azure Synapse Analytics is a unified cloud-based platform...

Big Data Certification Training Course in Gurgaon Build & automate Big Data Pipelines using Sqoop,...

Kafka Certification Training Course in Gurgaon Build realtime data pipelines using kafka using Kafka API’s...

Microsoft Fabric Data Engineer Certification Course in Gurgaon Microsoft Fabric is a unified cloud-based platform...