Big Data Certification Training Course in Gurgaon
Build & automate Big Data Pipelines using Sqoop, Hive, HDFS, Oozie & implement business transformation using PySpark that is processing tool used to build ETL jobs to configure Data Pipelines & perform all the business rules & validation across the pipeline using PySpark rich library. It combines Data warehousing, ETL Processing capability using Spark Engine to bring end-to-end (E2E) ETL solution from Data ingestion to hydration to transformation using Spark Executor.
- Develop Big Data Pipeline using HDFS, Sqoop, Spark & others to build Data Pipelines & use Hadoop ecosystem tools to perform Data transformation.
- Training program will provide interactive sessions with industry professionals
- Realtime project expereince to crack job interviews

- Course Duration - 3 months
- Get training from Industry Professionals
Train using realtime course materials using online portals & trainer experience to get a personalized teaching experience.
Active interaction in sessions guided by leading professionals from the industry
Gain professionals insights through leading industry experts across domains
24/7 Q&A support designed to address training needs
Big Data & Hadoop Certification Course Overview
Shape your carrer in building & automating Big Data Pipelines using Sqoop, Hive, HDFS, Oozie & implement business transformation using PySpark that is processing tool used to build ETL jobs to configure Data Pipelines & perform all the business rules & validation across the pipeline using PySpark rich library. It combines Data warehousing, ETL Processing capability using Spark Engine to bring end-to-end (E2E) ETL solution from Data ingestion to hydration to transformation using Spark Executor.
- Benefit from ongoing access to all self-paced videos and archived session recordings
- Success Aimers supports you in gaining visibility among leading employers
- Industry-paced training with realtime scenarios using HDFS, Hive & PySpark scripts/templates for automating Big Data Pipelines.
- Real-World industry scenarios with projects implementation support
- Live Virtual classes heading by top industry experts alogn with project implementation
- Q&A support sessions
- Job Interview preparation & use cases
Explain Big Data & Hadoop Engineers?
Big Data & Hadoop Engineers build Data Pipeline & Infrastructure using Big Data tools like, Sqoop, Flume, Hive, Spark & others while writing ETL templates. Sqoop & Flume automate the Data ingestion & transformation cycle that integrates with Spark to implement business transformations on Hybrid Cloud platforms (AWS, Azure, GCP & others).This training will provide hands-on training & covers HDFS, Sqoop, Spark, Hive, Oozie & other modules to build Data Ingestion & ELT & ETL workflows.
Role of Big Data & Hadoop Engineer?
Big Data & Hadoop Engineers build Data Pipeline & Infrastructure using Big Data tools like, Sqoop, Flume, Hive, Spark & others while writing ETL templates. Sqoop & Flume automate the Data ingestion & transformation cycle that integrates with Spark to implement business transformations on Hybrid Cloud platforms (AWS, Azure, GCP & others).This training will provide hands-on training & covers HDFS, Sqoop, Spark, Hive, Oozie & other modules to build Data Ingestion & ELT & ETL workflows.
Responsibilities include:
- Big Data & Hadoop Engineers use Visual Studio & others IDE’s to write ETL & Spark scripts to build Data Pipelines.
- Big Data Engineers manages the end-to-end Data life cycle using HDFS workflow and Spark templates.
- Develop and Design ETL workflows that automate Data Pipeline securely & seamlessly
- Success Aimers helps aspiring Big Data professionals to build, deploy, manage data pipelines using cloud environments & build ETL templates effectively & seamlessly.
- Design, Build & Deploying ETL scripts within cloud infrastructure securely & seamlessly.
Who should opt for Big Data Engineer course?
Big Data Engineer course accelerates/boost career in Big Data & Cloud organizations.
- Big Data Engineers – Big Data Engineers manages the end-to-end Data lifecycle from design, build & deploy using Hive workflow and Spark templates.
- Big Data Engineers – Implementing Big Data Pipelines using Hadoop & Ecosystem Tools (Sqoop, Hive, Spark & others)
- Big Data Developers – Build, Design & Automate Big Data Pipelines via Big Data workflows using Hadoop & Ecosystem Tools (Sqoop, Hive, Spark & others)
- Big Data Architect – Leading Data initiative within enterprise.
- Big Data & Cloud Engineers – Deploying Big Data Application using Hadoop & Ecosystem Tools (Sqoop, Hive, Spark & others) across environments seamlessly and effectively.
Prerequisites of Big Data Engineer Course?
Prerequisites required for the Big Data Engineer Certification Course
- High School Diploma or a undergraduate degree
- Python + JSON/YAML scripting language
- IT Foundational Knowledge along with DevOps and cloud infrastructure skills
- Knowledge of Cloud Computing Platforms like AWS, AZURE and GCP will be an added advantage.
Kind of Job Placement/Offers after Big Data Engineer Certification Course?
Job Career Path in Infrastructure(Cloud) Automation using Hadoop & Ecosystem Tools (Sqoop, Hive, Spark & others)
- Big Data Engineer – Build, Design Develop & Deploying Spark scripts within cloud infrastructure using Hadoop & Ecosystem Tools (Sqoop, Hive, Spark & others).
- Big Data Engineer – Design, Developed and build ELT & ETL workflows to drive key business processes/decisions.
- Big Data Architect – Leading Data initiative within enterprise.
- Big Data Engineers – Implementing Data Pipelines using using Hadoop & Ecosystem Tools (Sqoop, Hive, Spark & others)
- Cloud and Big Data Engineers –
- Build, Design Develop & Deploying Spark scripts within cloud infrastructure using Hadoop & Ecosystem Tools (Sqoop, Hive, Spark & others) across environments seamlessly and effectively.
| Training Options | Weekdays (Mon-Fri) | Weekends (Sat-Sun) | Fast Track |
|---|---|---|---|
| Duration of Course | 2 months | 3 months | 15 days |
| Hours / day | 1-2 hours | 2-3 hours | 5 hours |
| Mode of Training | Offline / Online | Offline / Online | Offline / Online |
Big Data & Hadoop Engineer Foundation Certification Course Curriculum
Start your carrer in building & automating Big Data Pipelines using Sqoop, Hive, HDFS, Oozie & implement business transformation using PySpark that is processing tool used to build ETL jobs to configure Data Pipelines & perform all the business rules & validation across the pipeline using PySpark rich library. It combines Data warehousing, ETL Processing capability using Spark Engine to bring end-to-end (E2E) ETL solution from Data ingestion to hydration to transformation using Spark Executor.
Big Data & Hadoop Ecosystem
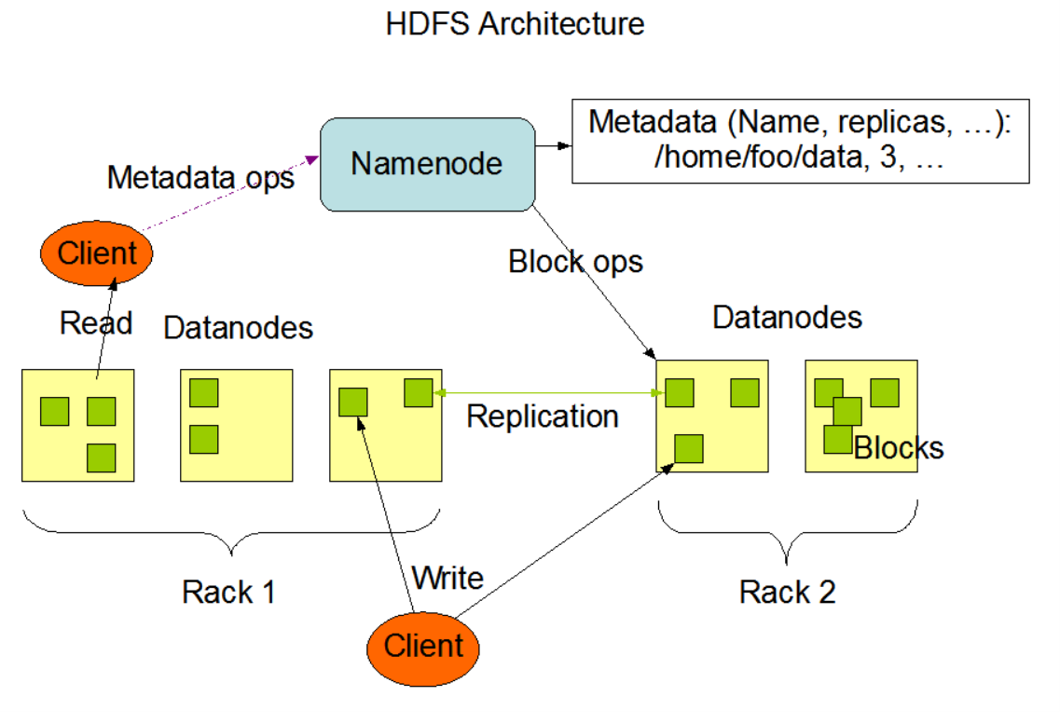
Apache Hadoop consists of Storage Layer (HDFS) that is used to store large volume of data in a distributed manner & top of that it consist of a Analytical Engine Map Reduce (MR) used for analytical purpose. Hadoop ecosystem consists of other tools like Sqoop, Hive, Pig, Hbase & other that is used to analyze the data stored inside HDFS. Sqoop is used to ingest data from structured sources into HDFS. Hive used Hive QL to analyze HDFS data using SQL style language. Flume is used to ingest realtime feeds into HDFS . HBase is a DBMS tool on top of HDFS. These components works together to handle large-volume of data storage processing & analysis in a distributed environment.

Course Details : Big Data & Hadoop Ecosystem
Understanding Big Data and Distributed Data Processing
- What is Big Data and How it Started
- Hadoop Architecture, History and Evolution
- Data Lake and Lakehouse Architecture
Using Hadoop’s Core: HDFS & Map Reduce
- HDFS: What it is, and how it works
- Alternate MovieLens download location
- Installing the MovieLens Dataset
- Install the MovieLens dataset into HDFS using the command line
- MapReduce: What it is, and how it works
- How MapReduce distributes processing
- MapReduce example: Break down movie ratings by rating score
- Code up the ratings histogram MapReduce job and run it
- Rank movies by their popularity
Setting up Cluster and doing hands on with Hadoop
- Cloudera Software Installation
- Hadoop Commands
- Row Storage vs Column Storage
- Serialized File Formats
Manage our HDFS Cluster
- YARN explained
- Yarn Schedulers
- Demo: Capacity Scheduler
- Yarn Sizing
- Hive Query Optimizations
- Join Strategies
- Spark Optimizations
- Name Node High Availability
- Label based scheduling
- Tez explained
- Use Hive on Tez and measure the performance benefit
- Apache MESOS explained
- Apache Zookeeper explained
- Simulating a failing master with Zookeeper
- Oozie explained
- Set up a simple Oozie workflow
- Zeppelin Overview
- Use Zeppelin to analyze movie ratings, part 1
- Use Zeppelin to analyze movie ratings, part 2
- Hue overview
Course Details - Apache Sqoop - Structured Data Ingestion into HDFS
- Sqoop Architecture
- Sqoop import
- Sqoop Connect
- Sqoop CodeGen
- Join Table Import
- Controlling Parallelism
- Sqoop multiple Mappers
- Sqoop Eval & change the file delimiter
- Incremental Import
- Password Protection
- Using Last Modified
- Import multiple File Formats
- Import multiple tables
- Handling null during import
- Sqoop export
- Sqoop Integration with Hive and HBase
- Sqoop Performance Tuning
Course Details - Apache Hive - Querying your Data Interactively – Analytical Tool on top of HDFS
- Hive Architecture
- Hive Metastore
- Hive Datatypes (Array, Map & Struct)
- Hive Table Types : Internal & External Tables
- Hive Query Language (HQL)
- Hive Optimization Techniques - (Partitioning (Static & Dynamic Partition), Hive Bucketing)
- Hive Joins - (Map Join, Bucket Map, SMB(SortedBucketMap) ,Skew)
- Hive File Formats (ORC+SEQUENCE+TEXT+AVRO+PARQUET)
- CBO (Cost Based Optimization)
- Vectorization
- Indexing (Compact + Bitmap)
- Hive Integration with TEZ & Spark
- Hive SerDer (Custom + Inbuilt)
- Hive integration NoSQL (HBase + MongoDB + Cassandra
- Thrift API (Thrift Server)
- UDF, UDTF & UDAF
- Hive Multiple Delimiters
- XML & JSON Data Loading HIVE.
- Aggregation & Windowing Functions in Hive
- Hive Connect with Tableau
- Hive Normalization vs Denormalization
- Implement SCD in Hive
- Execute Hive Queries using a Script
- Schema Evolution in Hive
- MSCK Repair
- Hive vs SQL
- Case Studies - (Sentimental Analysis Hive, E-Commerce Data Analysis using Hive, Real Estate Data Analysis Aviation Data Analysis using Hive)
Course Details - Apache Phoenix, Drill & Presto - Querying your Data Interactively
- Overview of Drill
- Setting up Drill
- Querying across multiple databases with Drill
- Overview of Phoenix
- Install Phoenix and query HBase with it
- Integrate Phoenix with Pig
- Overview of Presto
- Install Presto, and query Hive with it
- Query both Cassandra and Hive using Presto
Course Details - NoSQL Databases - Apache HBase & Cassandra
- HBase Architecture
- Master & Region Server
- Hbase Regions
- Scan over Snapshot
- In-Memory Compaction Strategies
- HBase and HDFS
- HBase Configuration
- HBase Shell
- HBase Data Model - (Conceptual View, Physical View, Namespace, Table, Column Family, Joins, ACID)
- HBase External API’s
- HBase and Spark
- HBase Snapshots
- -----Apache Cassandra------
- What is Cassandra
- Features of Cassandra
- Cassandra Architecture
- Cassandra Architecture Components
- Data replication
- Simple strategy
- Network Topology
- Data Partition
- Snitches
- Gossip Protocol
- Seed Nodes
- Cassandra Data Model - (Features of Cassandra Data Model, Cassandra Data Model Rules, Indexes, Collections, DML Statements, Compound Key)
- Cassandra Interfaces (CQL, Cqlsh, Cqlsh Shell Commands, CQL Data Definition, CQL Data Manipulation, ODBC Driver for Cassandra)
- Cassandra Advance Architecture - (What is Partitioning?, Features of Partitioners, Types of Partitioners, Replication of Data, Replication strategy , Types of Common replication Strategies, Tunable Consistency, Read Consistency,Write Consistency, Hinted handoff,Time to Live (TTL) Tombstones, Monitoring the Cluster, Monitoring the NodeTool, Monitoring with OpsCenter)
Course Details - Apache NiFi - Building Realtime Streaming Workflows
- Apache NiFi Basics
- NiFi User Interface
- Core NiFi Terminologies
- More on Flow Files on NiFi
- Types of Processors available in NiFi
- Processor Configuration, Connection & Relationship in NiFi
- Connection Queue & Back Pressure in NiFi
- Hands-On with Apache NiFi - (Working with Attributes & Content in NiFi , Working with Expression Language in NiFi, More on Expression Language Functions in NiFi, Working with Processor Group (PG), Input Port & Output Port in NiFi, Working with Templates in NiFi, Working with Funnel in NiFi, Working with Controller Services in NiFi, Working with Variable Registry in NiFi)
- Apache NiFi Advanced Concepts - (Flow File in NiFi, Flow File Expiration in NiFi, Data Provenance in NiFi)
- Monitoring in NiFi (Monitoring in NiFi, Monitoring NiFi using Reporting Task, Remote Monitoring NiFi using Reporting Task)
- NiFi Registry for Version Control - (Overview on NiFi Registry, Installation of NiFi Registry, Configuring NiFi and NiFi Registry to enable version control, Configuring NiFi Registry with multiple NiFi Instances, Configuring NiFi Registry to enable Git Persistence)
- NiFi Cluster for Heavy Lifting - (Overview of NiFi Clustering, Limitation in NiFi Clustering, NiFi Cluster Configuration using Embedded Zookeeper, NiFi Cluster Configuration Steps, NiFi Cluster Configuration using External Zookeeper, NiFi Cluster Configuration Steps in Single Machine)
- NiFi Custom Processor - (Overview of NiFi Clustering, Limitation in NiFi Clustering)
- Logging in NiFi - (Logging in NiFi, Pipeline Monitoring, Cluster and Resource Monitoring)
Course Details - Apache Oozie - Schedule ETL Workflows (Hadoop & Spark)
- What is Oozie
- Oozie Features
- Oozie Version
- Oozie Workflows
- Oozie Workflow Nodes
- Oozie Coordinator Jobs
- Running Oozie
- Oozie Bundle Jobs
Cloudera Hadoop Distribution (CDP Administration)
Cloudera Distribution is an enterprise ready Hadoop platform consisting of all the hadoop ecosystem tools like Sqoop, Flume, Hive, Oozie, Spark & others. It consist of pre-built Kerberos Authentication for Hadoop users & also has pre-built Encryption capability for the Data security. Also this platform can be deployed on-prem or on-cloud & can be used for Analytics & AI.

Course Details : Cloudera Hadoop Distribution (CDP Administration)
Installation of Cloudera Manager and CDH
- Deploying Virtual Machines on Amazon Web Service
- Configuring Prerequisites for Hadoop Installation
- Configuring Local Repository for Cloudera Manager and CDH
- Installing and Configuring MySQL Database for Cloudera Manager
- Installation and Configuration of Cloudera Manager
- Installation and Configuration of CDH
CDP - Proof of Concept Installation
- Deploying Master Virtual Machine in Azure Cloud
- Configuring Prerequisites on Master Host
- Configure Cloudera Manager Local Repository
- Installing Cloudera Manager Server
- Creating Cloudera Runtime Parcel Local Repository
- Deploying Virtual Machines for Worker Hosts
- Configure Prerequisites on Worker Hosts
- Configure Prerequisites on Worker Hosts - Part 2
- Deploying Cluster using Cloudera Manager - Part1
- Deploying Cloudera Cluster using Cloudera Manager - Part 2
CDP - Adding New Host to existing Hadoop Cluster
- Deploying new virtual machine on Amazon Web Service
- Adding new host to existing Hadoop Cluster using Cloudera Manager
- Configure Prerequisites on New host - Part 1
- Configure Prerequisites on New host - Part 2
- Adding new hosts to cluster using Cloudera Manager
Centralized Authentication Using Active Directory
- Deploying Windows Server 2012 on Amazon Web Service
- Installation and Configuration of Active Directory Server
- Integrating Linux Hosts with Active Directory for Centralized Authentication
CDP - Production Installation
- Configure prerequisites on Master
- Installing Cloudera Manager Server
- Deploy Worker Nodes Using ARM template
- Configure Prerequisites on Nodes
- Install Cloudera Manager Agent on Hosts
- Deploy CDP Cluster Using Cloudera Manager
Cloudera Manager Authentication using Active Directory
- Prepare AWS AMI for Cloudera Installation
- Install - Cloudera Data Hadoop (CDH) Quick Install
- Cloudera Installation Phases and Paths
- Cloudera Manager Introduction and Overview
- Cloudera Parcels
- Cloudera Repository Setup with Apache httpd
- Cloudera Installation Path B with local repository - AMI Prepare
- Cloudera Installation Path B - Manager Installation and Configuration
- Cloudera Installation Path B - Agent and CDH Installation and Configuration
- Add Cluster, Add Service and Delete Cluster life cycle
CDP - Validating Cluster
- Validating Cluster
CDP - Adding Services
- Adding Hive Service
- Validating Hive Service
- Creating ADLS Gen-2 and App ID
- Connecting ADLS Gen-2 Storage with CDP Cluster
- Adding HBase Service
- Creating Tables in HBase
- Adding Kafka Service
- Adding Spark Service
- Adding Solr service
CDP - Configure High Availability
- NameNode High Availability
- Resource Manager High Availability
- Hive Server High Availability
CDP - Active Directory Integration and Kerberos
- Deploying Windows Server
- Installing and Configuring Active Directory Service
- Linux Server Active Directory Integration
- Creating Users and Validating
- Connecting Hosts With Active Directory
- Enabling Kerberos using Active Directory
HDFS Basic Shell Commands
- HDFS Shell Commands
- HDFS Trash
HDFS High Availability HA - Concept, Setup, Configure,Test,Verify, Remove
- HDFS High Availability (HA) - Concepts
- HDFS High Availability (HA) - Setup
- HDFS High Availability (HA) - Test
- HDFS High Availability (HA) - Remove
HDFS Manage - Balancer, Maintenance, Quota Management, Canary Test
- HDFS Balancer
- HDFS Maintenance Mode
- HDFS Quota Management
- HDFS Canary Test
- HDFS Rack Awareness
HDFS Checkpoint, Understand, Manage, Work with Edits, FSIMage, Roll Edits
- HDFS Edits FSImage Introduction
- HDFS Checkpoint Introduction and Deepdive
- HDFS Edits FSImage - Offline Image View (OIV) and Offline Edits View (OEV)
- HDFS Roll Edits
- HDFS Save Namespace
HDFS Advanced - Snapshot, WebHDFS, Federation, Recovery, httpFS, Edge Node
- HDFS Snapshot
- HDFS Snapshot Policy
- HDFS Edge Node
- HDFS WebHDFS
- HDFS httpFS
- HDFS FSCK Utility
- HDFS Recovery
- HDFS Federation
- HDFS - Home Directory
Cloudera Manage- Commission, Decommission, Client Configuration, Host Template
- Cluster Commission and Decommission
- Cluster Client Configuration
- Cluster Host Template
LDAP - Install, Configure OS, phpLDAPAdmin Client
- OpenLDAP - phpLDAPAdmin - Installation and setup
- CentOS user authentication with OpenLDAP
YARN - Components, Submit MR
- YARN - Resource Manager, Node Manager , Scheduler Introduction
- YARN - Submit MapReduce Job : Single and Multiple Jobs
Resource Manager - Scheduler Types, Dynamic Resource Pool, High Availability
- YARN - Types of Resource Manager Summary
- YARN - Resource Manager - Static Service Pool
- YARN - Resource Manager - FIFO - First In First Out Scheduler
- YARN - Resource Manager - Fair Scheduler
- YARN - Resource Manager - Capacity scheduler
- YARN - Resource Manager - Dynamic Resource Pool Configuration
- YARN - Resource Manager - High Availability
Apache Zookeeper - Install, Configure
- Zookeeper - Introduction & Adding as Service
Apache Hive - Manage, SetUp HA, Beeline, WebHCat, HCatalog, Warehouse dirconfig
- Hive Introduction
- Hive Installation and Configuration
- Hive Data set Preparation for Demo
- Hive Client Demo - Hive Shell - Beeline Shell Demo
- Hive Client - Experience Hive Query with HUE - Query, Visualize and Analyze
- Hive High Availability -HA
- Hive WebHCat and HCatalog
- Hive Warehouse Directory and Metastore DB Configuration
Apache Oozie - Install Configure
- Apache Oozie Introduction, Installation and Setup
Hadoop User Interface (HUE) - SetUp, Install, LDAP Integration, Extended ACL
- HUE - Hadoop User Experience - Setup, Installation and Introduction
- HUE - OpenLDAP Integration for Authentication
- HDFS Extended Access Control List (ACL)
Sentry - Install, Configure, Role based Authentication, LDAP Integration
- Sentry Introduction and Role Based Authorization Concepts
- Sentry Installation and Configuration
- HUE Security Module Configuration and Integration with Sentry for Authorization
- Hive Table Authorization with Sentry - Practical Scenario
- Cloudera Manager - OpenLDAP Integration for Authentication
- Installing Sentry Service
- Sentry Configuration
- Creating Sentry Admin Role in Hive
- Hive authorization using Sentry
Impala - Install, Configure, Compare with Hive, Architecture
- Impala Introduction and Concepts
- Impala Compare with Hive - Architecture and Performance
- Impala Installation and configuration
Kerberos - Install, Configure, Verify, Secure
- Kerberos Introduction, Architecture and Authentication Process
- Kerberos Prepare Server and Client for Setup and Configuration
- Kerberos - Configure Cloudera to Kerberize the Cluster
- Kerberos - Working with Keytab and Service Ticket
- Enabling Kerberos using Active Directory as Kerberos Server
Upgrading Cloudera Manager
- Upgrade Cloudera Manager Part 1
- Cloudera Manager Upgrade - Part 2
- Starting Failed Cloudera Manager Services
CDH Upgrade
- Upgrade CDH using Local Parcel Repository
Rack Awareness
- Configuring Rack Awareness Using Cloudera Manager
High Availability
- Enabling Namenode High Availability Using Cloudera Manager
- Enabling Resource Manager High Availability Using Cloudera Manager
Access Control List (ACL)
- Enabling and Working with HDFS Access Control List ( HDFS ACL )
Installing and Configuring Hadoop Ecosystem Components
- Installing Hive Service
- Installing Hbase Service
- Installing and Configuring Hue
- Installation and Configuration of Impala
- Installation of Kafka
Sqoop - Data Ingestion
- Sqoop Introduction, Architecture Installation and Configuration
- Sqoop Import and Export between HDFS, Hive, HBase and RDBMS
HBase - Hadoop Base - NoSQL Database
- NoSQL - HBase Service - Introduction and Installation
- HBase - HUE Configuration to Work with HBase
- HBase - Working with Tables in HUE Editor
Flume - Single and Multi Agent Data Ingestion
- Flume Installation and Configuration - Single Agent Scenario
- Flume Multi Agent Configuration - Log collection from multiple nodes of Cluster
HDFS Encryption
- HDFS - Encrypted Zone, Keystore configuration
Apache Spark Installation, Configuration and Administration
- Spark Introduction
- Spark Architecture
- Spark Installation
- Spark Submit Job - Standalone Cluster
Apache Kafka Installation, Configuration and Administration
- Kafka Introduction
- Kafka Installation
- Kafka components and Architecture
- Kafka - Flume Integration
- Kafka Administration
Hadoop Benchmarking
- HDFS Terasort, Teragen, Teravalidate
- TestDFSIO
Memory Management - Container JVM, Role,Node Memory and Performance Management
- Node Memory management . Calculate heap requirement and optimal heap for roles
- Namenode Heap Calculation
HDFS Redaction,IO, Compression, distcp, file copy
- HDFS Redaction
- Compression
- HDFS Copy and distcp
Reports, Charts and Dashboard
- Charts and Dashboard
Cloudera 6
- New Features in Cloudera 6
- Cloudera 6 System Prepare
- Cloudera 6 Quick Install
Apache Spark & its related Ecosystem
PySpark is a data processing tool that is used to build ETL jobs to configure Data Pipelines & perform all the business rules & validation across the pipeline using PySpark rich library. It combines Data warehousing, ETL Processing capability using Spark Engine to bring end-to-end (E2E) ETL solution from Data ingestion to hydration to transformation using Spark Executor.

Course Details : Apache Spark & its related Ecosystem
Introduction to Apache Spark (Spark Installation, Components & Architecture)
- What is Apache Spark
- Apache Spark System Architecture
- Apache Spark Components & Architecture
- Spark Platform and Development Environment
- What is Databricks Cloud
- Create your Databricks Free Account
- Spark Installation
- Spark Main Components
- Spark & its features
- Deployment Modes of Spark
- Introduction to PySpark Shell
- Submitting PySpark Jobs
- Utilizing Spark Web UI
Getting started with Spark Programming
- Starting Point - Spark Session
- Introduction to Spark Session
- Spark Object and Spark Submit Part 1
- Spark Object and Spark Submit Part 2
- Spark Object and Spark Submit Part 3
- DataFrame – A view to Structured data
- DataFrame Transformations and Actions
- DataFrame Concepts
- Exploring DataFrame Transformations
- Creating Spark DataFrame
Spark Cluster Execution Architecture
- Full Architecture
- YARN As Spark Cluster Manager
- JVMs across Clusters
- Commonly Used Terms in Execution Frame
- Narrow and Wide Transformations
- DAG Scheduler Part 1
- DAG Scheduler Part 2
- DAG Scheduler Part 3
- Task Scheduler
Spark Shared Variables
- Broadcast Variable
- Accumulator Variable
Spark SQL Introduction & Architecture
- Spark SQL Architecture Part 1
- Spark SQL Architecture Part 2
- Spark SQL Architecture Part 3
- Spark SQL Architecture Part 4
- Spark SQL Architecture Part 5
- Spark SQL Architecture Part 6
- Spark SQL Architecture Part 7
- Spark SQL Architecture Part 8
- Working with SQL Context and Schema RDDs
- User Defined Functions (UDFs) in Spark SQL
- Data Frames, Datasets, and Interoperability with RDDs
- Loading Data from Different Sources
- Integration of Spark with Hive for Data Warehousing
Spark Session Features
- Introduction to Spark Session
- Spark Object and Spark Submit Part 1
- Spark Object and Spark Submit Part 2
- Spark Object and Spark Submit Part 3
- Version and Range
- createDataFrame
- sql
- Table
- sparkContext
- udf
- read-csv
- read-text
- read-orc and parquet
- read-json
- read-avro
- read-hive
- read-jdbc
- Catalog
- newSession and stop
DataFrame Fundamentals
- Introduction to DataFrame
- DataFrame Features - Distributed
- DataFrame Features - Lazy Evaluation
- DataFrame Features - Immutability
- DataFrame Features - Other Features
- Organization
DataFrame ETL
- Introduction to Transformations and Extraction
- DataFrame APIs Introduction Extraction
- DataFrame APIs Selection
- DataFrame APIs Filter or Where
- DataFrame APIs Sorting
- DataFrame APIs Set
- DataFrame APIs Join
- DataFrame APIs Aggregation
- DataFrame APIs GroupBy
- DataFrame APIs Window Part 1
- DataFrame APIs Window Part 2
- DataFrame APIs Sampling Functions
- DataFrame APIs Other Aggregate Functions
- DataFrame Built-in Functions Introduction
- DataFrame Built-in Functions - New Column Functions
- DataFrame Built-in Functions - Column Encryption
- DataFrame Built-in Functions - String Functions
- DataFrame Built-in Functions - RegExp Functions
- DataFrame Built-in Functions - Date Functions
- DataFrame Built-in Functions - Null Functions
- DataFrame Built-in Functions - Collection Functions
- DataFrame Built-in Functions - na Functions
- DataFrame Built-in Functions - Math and Statistics Functions
- DataFrame Built-in Functions - Explode and Flatten Functions
- DataFrame Built-in Functions - Formatting Functions
- DataFrame Built-in Functions - Json Functions
- Need of Repartition and Coalesce
- How to Repartition a DataFrame
- How to Coalesce a DataFrame
- Repartition Vs Coalesce Method of a DataFrame
- DataFrame Extraction Introduction
- DataFrame Extraction - csv
- DataFrame Extraction - text
- DataFrame Extraction - Parquet
- DataFrame Extraction - orc json
- DataFrame Extraction - avro
- DataFrame Extraction - hive
- DataFrame Extraction - jdbc
DataFrame Transformations
- Adding, Removing, and Renaming Columns
- DataFrame Column Expressions
- Filtering and removing duplicates
- Sorting, Limiting and Collecting
- Transforming Unstructured data
- Transforming data with LLM
Working with different Data Types
- Working with Nulls
- Working with Numbers
- Working with Strings
- Working with Date
- Working with Timestamps
- Handling Time Zone Information
- Working with Complex Data Types
- Working with JSON data
- Working with Variant Type
Joins in Spark DataFrame
- Introduction to Joins in Spark
- Inner Joins
- Outer Joins
- Lateral Join
- Other Types of Joins
Aggregation in Spark
- Simple Aggregation
- Grouping Aggregation
- Multilevel Aggregation
- Windowing Aggregation
UDF and Unit Testing
- User-Defined Functions
- Vectorized UDF
- User Defined Table Functions
- Unit Testing Spark Code
Spark Execution Model
- Execution Methods - How to Run Spark Programs?
- Spark Distributed Processing Model - How your program runs?
- Spark Execution Modes and Cluster Managers
- Summarizing Spark Execution Models - When to use What?
- Working with PySpark Shell - Demo
- Installing Multi-Node Spark Cluster - Demo
- Working with Notebooks in Cluster - Demo
- Working with Spark Submit - Demo
Spark Programming Model and Developer Experience
- Creating Spark Project Build Configuration
- Configuring Spark Project Application Logs
- Creating Spark Session
- Configuring Spark Session
- Data Frame Introduction
- Data Frame Partitions and Executors
- Spark Transformations and Actions
- Spark Jobs Stages and Task
- Understanding your Execution Plan
Spark Structured API Foundation
- Introduction to Spark APIs
- Introduction to Spark RDD API
- Working with Spark SQL
- Spark SQL Engine and Catalyst Optimizer
Spark Data Sources and Sinks
- Spark Data Sources and Sinks
- Spark DataFrameReader API
- Reading CSV, JSON and Parquet files
- Creating Spark DataFrame Schema
- Spark DataFrameWriter API
- Writing Your Data and Managing Layout
- Spark Databases and Tables
- Working with Spark SQL Tables
Spark DataFrame and Dataset Transformations
- Introduction to Data Transformation
- Working with DataFrame Rows
- DataFrame Rows and Unit Testing
- DataFrame Rows and Unstructured data
- Working with DataFrame Columns
- Misc Transformations
DataFrame Joins
- DataFrame Joins and column name ambiguity
- Outer Joins in DataFrame
- Internals of Spark Join and shuffle
- Optimizing your joins
- Implementing Bucket Joins
Optimizing Data Frame Transformations
- General Join Mechanisms - (Shuffled Join, Optimized Join, Broadcast Join,Caching & Checkpointing, Skew Joins)
- Partitioning - (Repartition & Coalesce, Shuffle Partitions )
- Performance Tuning Problems - (Optimizing Cluster Resource Allocation, Serialization Problem, Fixing Data Skew (Data Skewness) & Straggling Task)
- Partitioning - (Repartition & Coalesce, Shuffle Partitions, Custom Partitioners Column Pruning )
Optimizing Apache Spark on Databricks (Performance & Optimization)
- Five Most Common Problems with Spark Applications
- Key Ingestion Concepts
- Optimizing with Adaptive Query Execution & Dynamic Partition Pruning
- Designing Clusters for High Performance
- Join Strategies_01_Broadcast Join
- Join Strategies_02_Shuffle Hash Join
- Join Strategies_03_Shuffle Sort Merge Join
- Join Strategies_04_Cartesian Product Join
- Join Strategies_05_Broadcast Nested Loop Join
- Join Strategies_06_Prioritize different Join strategy
- Driver Configurations
- Executor Configurations Part 1
- Executor Configurations Part 2
- Configurations in spark-submit
- Parallelism Configurations
- Memory Management
Capstone Project
- Project Scope and Background
- Data Transformation Requirement
- Setup your starter project
- Test your starter project
- Setup your source control and process
- Creating your Project CI CD Pipeline
- Develop Code
- Write Test Cases
- Working with Kafka integration
- Estimating resources for your application
Design, Develop & Build Big Data through a Data Ingestion (ELT) pipeline with Hadoop Ecosystem Tools (Sqoop, Hive ,Spark & others)
Project Description : Data from multiple data sources will be ingested into HDFS using Sqoop & Spark Connectors using the Data Pipeline pipeline that containers raw, curated & derived zones. The Raw layer contains the hydrated data from the source which is then pushed to curated after Data cleansing & standardization & finally to derived zone for reporting purpose. The whole contains series of automated Spark jobs using Oozie scripts.
Also Oozie manages the end-to-end Data life cycle jobs automation using Oozie workflow and Job templates.
Project 2
Automated Ingestion Framework Pipeline (Hadoop Platform)
The whole Data Ingestion pipeline will be automated through Hadoop & Spark jobs where in it deploys the Hadoop components like Sqoop, Hive, Flume, HDFS & Spark tables into Data storage layer before triggering the Data flow through the pipeline. Data will be extracted from the source like contact centers & others & this whole pipeline is realtime pipeline that triggers whenever data arrives from the source into Kafka using Kafka source and sink connecters that triggers the deployment process.
Hours of content
Live Sessions
Software Tools



After completion of this training program you will be able to launch your carrer in the world of Big Data being certified as Big Data Certified Professional.
With the Big Data Certification in-hand you can boost your profile on Linked, Meta, Twitter & other platform to boost your visibility

- Get your certificate upon successful completion of the course.
- Certificates for each course












Designed to provide guidance on current interview practices, personality development, soft skills enhancement, and HR-related questions

Receive expert assistance from our placement team to craft your resume and optimize your Job Profile. Learn effective strategies to capture the attention of HR professionals and maximize your chances of getting shortlisted.

Engage in mock interview sessions led by our industry experts to receive continuous, detailed feedback along with a customized improvement plan. Our dedicated support will help refine your skills until your desired job in the industry.

Join interactive sessions with industry professionals to understand the key skills companies seek. Practice solving interview question worksheets designed to improve your readiness and boost your chances of success in interviews

Build meaningful relationships with key decision-makers and open doors to exciting job prospects in Product and Service based partner

Your path to job placement starts immediately after you finish the course with guaranteed interview calls
Why should you choose to pursue a Big Data & Hadoop course with Success Aimers?
Success Aimers teaching strategy follow a methodology where in we believe in realtime job scenarios that covers industry use-cases & this will help in building the carrer in the field of Big Data & Hadoop also delivers training with help of leading industry experts that helps students to confidently answers questions confidently & excel projects as well while working in a real-world
What is the time frame to become competent as a Big Data & Hadoop engineer?
To become a successful Big Data & Hadoop Engineer required 1-2 years of consistent learning with dedicated 3-4 hours on daily basis.
But with Success Aimers with the help of leading industry experts & specialized trainers you able to achieve that degree of mastery in 6 months or one year or so and it’s because our curriculum & labs we had formed with hands-on projects.
Will skipping a session prevent me from completing the course?
Missing a live session doesn’t impact your training because we have the live recorded session that’s students can refer later.
What industries lead in Big Data & Hadoop implementation?
Manufacturing
Financial Services
Healthcare
E-commerce
Telecommunications
BFSI (Banking, Finance & Insurance)
“Travel Industry
Does Success Aimers offer corporate training solutions?
At Success Aimers, we have tied up with 500 + Corporate Partners to support their talent development through online training. Our corporate training programme delivers training based on industry use-cases & focused on ever-evolving tech space.
How is the Success Aimers Big Data & Hadoop Certification Course reviewed by learners?
Our Big Data & Hadoop Engineer Course features a well-designed curriculum frameworks focused on delivering training based on industry needs & aligned on ever-changing evolving needs of today’s workforce due to Data & AI. Also our training curriculum has been reviewed by alumi & praises the thoroguh content & real along practical use-cases that we covered during the training. Our program helps working professionals to upgrade their skills & help them grow further in their roles…
Can I attend a demo session before I enroll?
Yes, we offer one-to-one discussion before the training and also schedule one demo session to have a gist of trainer teaching style & also the students have questions around training programme placements & job growth after training completion.
What batch size do you consider for the course?
On an average we keep 5-10 students in a batch to have a interactive session & this way trainer can focus on each individual instead of having a large group
Do you offer learning content as part of the program?
Students are provided with training content wherein the trainer share the Code Snippets, PPT Materials along with recordings of all the batches

Apache Airflow Training Course in Gurgaon Orchestrating ETL pipelines using Apache Airflow for scheduling and...

AWS Glue Lambda Training Course in Gurgaon AWS GLUE is a Serverless cloud-based ETL service...

Azure Data Factory Certification Training Course in Gurgaon Orchestrating ETL pipelines using Azure Data Factory...

Azure Synapse Certification Training Course in Gurgaon Azure Synapse Analytics is a unified cloud-based platform...

Kafka Certification Training Course in Gurgaon Build realtime data pipelines using kafka using Kafka API’s...

Microsoft Fabric Data Engineer Certification Course in Gurgaon Microsoft Fabric is a unified cloud-based platform...

PySpark Certification Training Course in Gurgaon PySpark is a data processing tool that is used...